In March 2026, a transformers maintainer posted a screenshot in Slack. The Transformers repository was receiving more pull requests per day than a human team could review. Most of them came from AI coding agents. The maintainer’s message was blunt: “I think we need to do something drastic.”
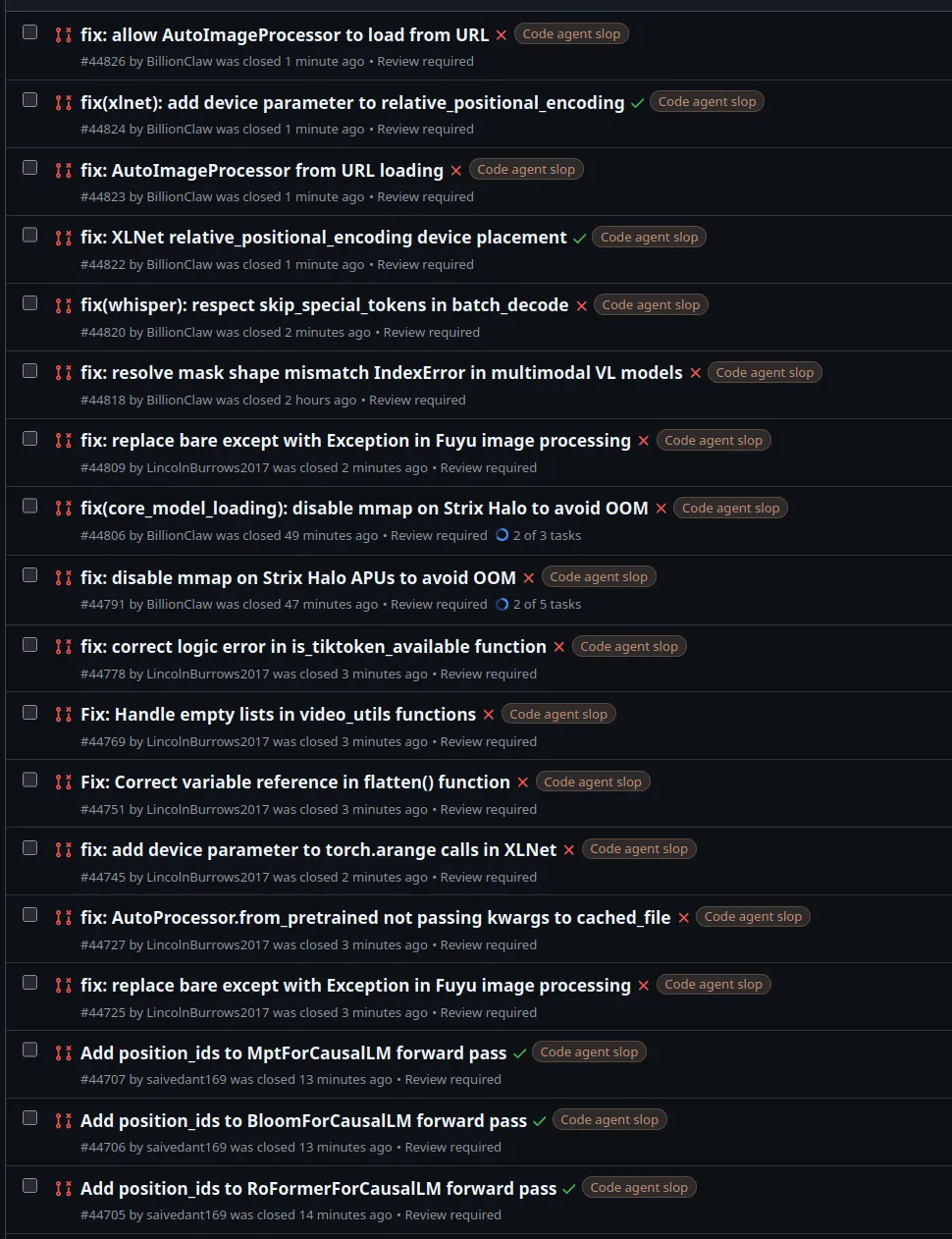
This problem is not unique to Transformers. Every large open source project on GitHub has been dealing with the same thing. Coding agents like Codex, Claude Code, and their wrappers make it trivial for anyone to fork a repository, point an agent at an issue, and open a pull request in seconds. Sometimes even without direct instruction from humans.
The volume is unprecedented, but the maintainers reviewing them are the same small teams they have always been. Most individual contributions are incomplete or incorrect, but not random. Usually, they cluster around real problems in the codebase that need to be fixed, or rapidly respond to issues en masse.
To understand this, we started a project at Hugging Face to study what was arriving on Transformers. We didn’t set out to solve it, but we wanted to know whether agent contributions contained useful signal, and whether there was a way to extract it from the noise.
Ultimately, we don’t want to block or discourage people from contributing to transformers, even if the code is sub par, we pride ourselves on educating our community. And we want to be ready for the next era of AI development, with the same culture that has brought us this far.
The shape of the problem
Transformers receives more than a hundred issues and pull requests with activity on any given day. A single maintainer on ‘watch’ is usually able to triage all of them, whilst the rest of the team focuses on longer running projects like features or new models. Before agent-generated PRs, this was already hard work.
The AI PRs fall into a few categories. Some are pure noise: superficial refactors, reformatting, or changes that break things the agent did not understand. Some are duplicates, where twenty agents all attempt the same bug fix after an issue is filed. Some few are useful fixes. The distribution is heavily skewed toward noise.
We classified and validated 772 PRs from the dataset. 326 (42%) added features — new model implementations, new format support, new APIs. 299 (39%) fixed defects. 97 (13%) were documentation, mostly translations. The remaining 50 were CI changes, typing cleanups, and other chores.
The defect fixes cluster around a small number of hotspots: tokenizer handling, model loading, dtype mismatches, and multimodal pipelines. These are the areas where agents consistently find real problems. If 28 PRs independently flag tokenizer handling bugs, that is a collective signal about a weak area in the codebase. Regardless of whether any individual fix is correct, there is probably something there that we want to fix.
The monthly PR rate nearly quadrupled over the period we studied. In Q3 2025, the repository received roughly 44 AI classified PRs per month. By April 2026, that number was 167. The composition shifted too: documentation contributions (mostly translations) dropped from 24% to 5%, while feature PRs (new model implementations, new format support) grew from 31% to 43%. Defect fixes held steady at 36–44% throughout.
Heuristic gates
When we discussed this at Hugging Face, we first considered simple heuristics that block bad actors. For example, account age or successfully merged PRs. Though potentially effective, these come with the high price of excluding new contributors.
We all remember the feeling of contributing to open source projects for the first time, and nothing should take that away from people. Agent or not.
Contributing guidelines
Next, we discussed honor codes in CONTRIBUTING.md. For example, clear warnings in the contributing guide, detailed explanations of the rules, and a commitment to progressive enforcement. We implemented this and it has considerably refined the agent contributions problem today.
Thanks for listening community!
The real contributors
Many of the first contributors are real people (CS students, junior developers) who think they are being helpful by fixing a bug with an agent. They lack the domain knowledge or project overview to tell whether their agent’s output is correct. Blocking them outright will probably just deter them from our projects, or worse open source contributions generally. But reviewing their PRs takes the same time as reviewing anyone else’s, and they now account for the majority of incoming contributions.
We are quickly moving to a world where most code will be written by agents, and what we want is not to block good contributions made consciously by people steering the agents, but block low-effort completely autonomous contributions from making it to main.
The core problem is that the people submitting low-effort PRs do not know they are low-effort.
Signal in the noise
One cluster makes the duplication problem concrete. Issue #43979 asked for a mechanical refactor: migrate model output tracing to standardized decorators. Between PR #43996 and PR #44722, thirty-nine separate contributors submitted PRs applying this pattern to different model files. The PRs are nearly identical in structure. Each one touches a single model, applies the same decorator swap, and references the same issue. A maintainer reviewing them individually would do the same cognitive work thirty-nine times. A single combined PR could replace all of them.
This inspired our project: Token Donations. What if, instead of filtering these PRs, we treated them like token donations — contributions of compute and attention that identify real problems, even when the fixes themselves are wrong?
The project
We wanted to see if we could treat agent contributions as donations. The users sending them meant well. Their agents had, in many cases, identified real issues. The fixes were often wrong or incomplete, but the signal was valid. The file has a bug, this function handles an edge case incorrectly, or the docs are outdated.
The project had two parts. First, build tooling to cluster, deduplicate, and assess the incoming PRs at scale. Second, run an experiment we called Transformers Thunderdome: take a fork of the repository and use agents to merge every open PR and see what breaks. The point was not to produce a production grade repository. It was to consume all the donated fixes, see what survived by benchmarking and testing transformers, and share the learnings with the team and community.
The tooling
Early on we connected with the OpenClaw team, who are also building open source triage tooling, because they are experiencing the same problem at a larger scale. They had already built clustering, triage, and merge automation tools. We shared notes and tools with each other, so here we include some of their tools as well.
We found and built several experimental tools for this to work. They each approach the same problem from different angles and at different layers. None of them, alone, solves the triage problem but they can be used to form custom pipelines.
Swarm Sweeper (huggingface/swarm-sweeper) scrapes PRs, issues, and contributor profiles from GitHub into a Hugging Face dataset. It computes code similarity using IDF-weighted search and runs a clustering algorithm to group related contributions. It can publish an API server to a Space or format its output for browsable search or in a dashboard.
pr-search-cli (huggingface/pr-search-cli) is a command-line frontend to Swarm Sweeper’s output. It is packaged for uvx so there is no setup: uvx pr-search-cli@latest issues list returns clusters immediately. The clustering uses both hard edges (PRs that reference the same issue) and soft edges (PRs whose code changes or descriptions look similar).
GHReplica and PRTags (dutifuldev/ghreplica, dutifuldev/prtags) are Onur Solmaz’s GitHub API cache and tagging manager. GHReplica mirrors repository data through webhooks and backfill, serving it over the same API as GitHub but without rate limits. PRTags manages cluster assignments on top of that data and can automatically post comments on PRs linking them to their duplicates.
GitCrawl (openclaw/gitcrawl) is built by the OpenClaw team to scrape GitHub data into a SQLite database and provide cluster management. It started as pwrdrvr/ghcrawl, was forked by Vincent Koc to add LLM-based analysis and file-hash clustering, then rewritten in Go for OpenClaw. Clustering uses text-embeddings-large with an optional LLM-generated summary step. The stable algorithm combines MinHash and SimHash based on Jaccard distance over code diffs, files touched by changes, and LLM analysis of the diffs.
ClawSweeper and ClownFish (openclaw/clawsweeper, openclaw/clownfish) are OpenClaw’s triage tools. ClawSweeper does brute-force parallel analysis of issues against the main branch. ClownFish acts on the largest clusters from GitCrawl, deduplicating and preparing PRs for maintainer review through an inbox pattern driven by Markdown files.
ACPX (openclaw/acpx) is the agent automation framework used to orchestrate merge flows. It drives agents through multi-step workflows. In this case, observe a cluster, check out the PRs, attempt a merge in a worktree, assess the result. (huggingface/pr-merger) contains the ACPX workflows for processing clusters or large batches of PRs into combined merges.
Swarm Sweeper (huggingface/swarm-sweeper) is the Hugging Face repository for the Swarm Sweeper side of this work.
Transformers Thunderdome
We wired the tools above into an end-to-end pipeline using ACPX. The pipeline takes a cluster of related PRs, checks them out into a worktree on a fork at evalstate/transformers, attempts a merge, and has an agent assess whether the combined result is valid. Each merged PR includes a comment with the full agent trace showing the reasoning.
Some clusters merged cleanly. The agent identified that multiple PRs fixed the same underlying bug and combined the best parts of each. Other clusters were rejected because the agent determined the fix had already been merged upstream. For instance, three separate contributors tried to add a feature that was already in main. The raw traces are published as datasets at evalstate/all-defects and evalstate/transformers-merge-experiments.
The traces are useful because they show the protocol, not just the outcome. In one batch, the agent merged six defect PRs in sequence and reran validation after each integration. In another, it handled a more typical mixed batch: some PRs were merged or patched, one was aborted because the codebase had moved on, and one was reset after validation failed. Below you can explore that trace.
The combined PR containing the merged results is at evalstate/transformers#42.
What we found
Clustering works
The clustering works. Both the embedding-based approach (GitCrawl, ClownFish) and the hard/soft-edge approach (Swarm Sweeper, pr-search-cli) identify genuine duplicates. They disagree on edge cases, and neither is complete on its own. Running an agent with access to both produces better groupings than either alone, but it consumes an extreme amount of tokens.
Duplication is the norm
The duplicate rate is high. When a visible bug is filed as an issue, it is common to see ten or twenty PRs appear within hours, all attempting the same fix. Most of these PRs are close enough in content that an agent can combine them. The combined version is usually better than any individual submission because it picks the cleanest implementation from the group.
The bottleneck is humans, then tokens
The triage bottleneck is real and it is not primarily a technology problem. The long standing issue is a lack of human resources, but that is given and not something an agent can or should solve. The next bottleneck is token consumption. Running a quality filter over every incoming PR depletes API subscriptions in hours. The tooling helps with prioritization and deduplication, but someone still has to review the output.
Benchmarking the merge
The merged fork is still a copy of transformers that loads models, runs tokenizers, and produces predictions the same way the original does. To verify that hundreds of bulk-merged agent PRs did not break anything, we used the fork to run inference on three small models and scored them with lighteval across three standard benchmarks. The “Main” column is stock transformers; “thunderdome” is the fork after all the merges. If the agent PRs introduced a regression in model loading, tokenization, or forward pass logic, the scores would diverge.
| Task | Model | Main | thunderdome | Delta |
|---|---|---|---|---|
arc_challenge | SmolLM2-135M-Instruct | 0.0000 | 0.0000 | +0.0000 |
arc_challenge | SmolLM2-360M-Instruct | 0.3000 | 0.3000 | +0.0000 |
arc_challenge | Qwen3-0.6B | 0.1000 | 0.1000 | +0.0000 |
gsm8k | SmolLM2-135M-Instruct | 0.0500 | 0.0500 | +0.0000 |
gsm8k | SmolLM2-360M-Instruct | 0.3000 | 0.3000 | +0.0000 |
gsm8k | Qwen3-0.6B | 0.2500 | 0.2500 | +0.0000 |
hellaswag | SmolLM2-135M-Instruct | 0.0000 | 0.0000 | +0.0000 |
hellaswag | SmolLM2-360M-Instruct | 0.3000 | 0.3000 | +0.0000 |
hellaswag | Qwen3-0.6B | 0.1500 | 0.1500 | +0.0000 |
Every delta is zero. Hundreds of changes across model files, tokenizer logic, and utility functions, and none of them shifted a single benchmark score. The merged fork produces identical outputs to stock transformers. The fixes were either neutral or touched code paths these benchmarks do not exercise. Either way, nothing broke.
In reality, this is a high-level evaluation of a few models on a few benchmarks. In production, we want to go further than this and compare CI across both versions.
What this means
The contributors sending agent-generated PRs are, for the most part, not adversarial. They want their fix reflected in the repository for an array of reasons; to improve the projects, to help their project, to advance their career. All of these are valid motivations to contribute to a project. However, some contributors do not have the context or the skill to evaluate whether the agent’s output is correct. The maintainers do have that context but do not have the bandwidth to evaluate hundreds of submissions.
The tools described here sit between those two groups. They cluster the incoming contributions, surface duplicates, assess contributor reputation, and in some cases combine the best parts of multiple PRs into a single reviewable unit. They do not replace human review. They reduce the number of things a human has to look at.
This is an early pass at the problem. The clustering will get better. The merge workflows will need to become more reliable. The token cost of running triage agents will come down. But the core dynamic of more contributions arriving than maintainers can process, is not going away. If anything, it will accelerate.
Open source projects that want to stay open to contributions will need tooling like this. Not to block agents, but to make the volume manageable. The signal is in there. You need a way to find it.
This project was a collaboration between Hugging Face and OpenClaw. Contributors: Ben Burtenshaw, Shaun Smith, Onur Solmaz, Vincent Koc. The Transformers team — Matt Carrigan, Andi Marafioti, Anton Vlasjuk, Cyril Vallez, Pedro Cuenca, Tarek Ziadé, and others — provided feedback and access throughout.
Repositories
- huggingface/swarm-sweeper — GitHub scraper, clustering, dataset publishing
- huggingface/pr-search-cli — CLI frontend to Swarm Sweeper output
- huggingface/pr-merger — ACPX merge workflows
- openclaw/acpx — Agent automation framework
- openclaw/gitcrawl — GitHub data mirror and clustering (Go)
- openclaw/clawsweeper — Brute-force issue analysis
- openclaw/clownfish — Cluster-driven PR triage
- dutifuldev/ghreplica — GitHub API cache
- dutifuldev/prtags — Cluster tagging and PR annotation